Reinforcement Learning
May – July 2020
-
I learnt about the concepts and applications of reinforcement learning in the projects for this class.
- Specifically, I learnt how to :
- apply tabular methods to discrete space problems,
- apply continuous methods to continuous space problems,
- study and understand game theory concepts,
- learn about solutions to solving Partially Observable Markov Decision Processes (POMDPs) and
- replicate results from research papers when details are left out.
-
Tools used: Python, OpenAIGym
- Methods used
- Temporal Difference methods
- TD(λ), Q-Learning, SARSA
- Approximate Methods
- Deep Q-Learning using Neural Networks i.e. DQN
- Game theory concepts
- Nash equilibrium, Folk Theorem, Subgame Perfect, Friend-Foe Q,COCO, Correlated Equilibrium.
- Temporal Difference methods
Selected Results
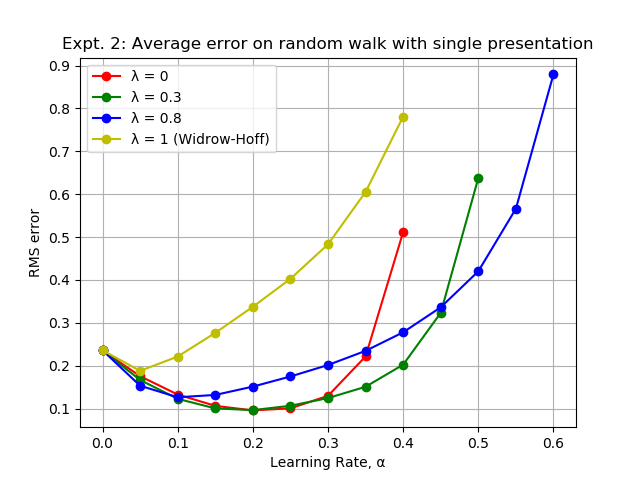
Figure 1: TD:The intermediate values of λ < 1 do better than TD(1). In particular, TD(1) continues to perform poorly as seen in the previous experiment. Amongst TD methods, lower values of λ like 0 and 0.3 do better than higher values like 0.8.
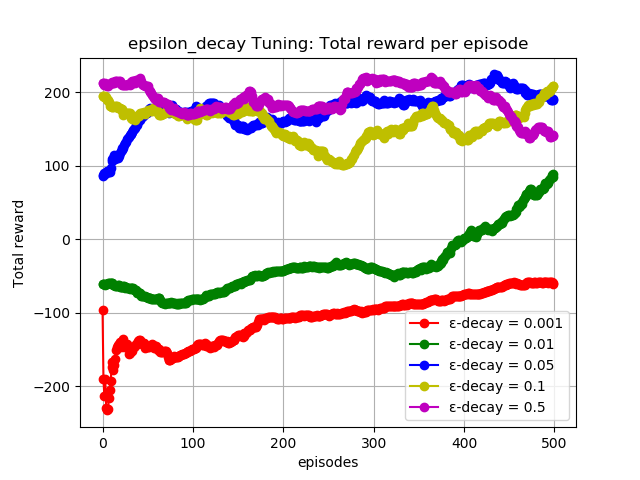
Figure 2: DQN:HP tuning for Lunar Lander:A smaller value of ε-decay = 0.05 allows the agent to balance exploration and exploitation better than other values in the range of available values.
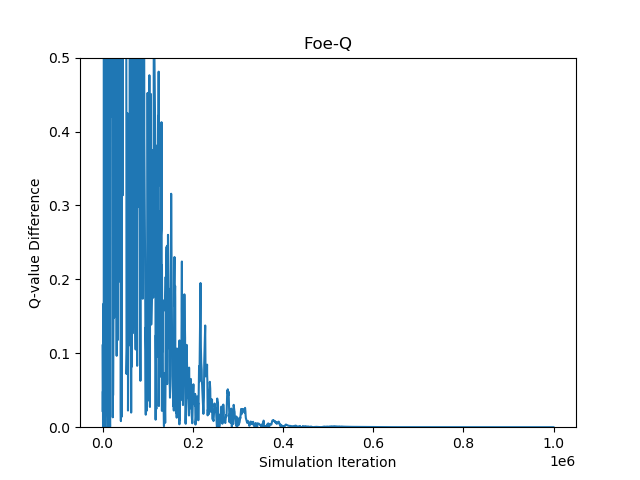
Figure 3:Linear Programming: For the game of Soccer(two player, zero-sum, repeated game with imperfect information.) Foe-Q algorithm converges within 5 x 105 episodes.